
[자료구조]#5_트리
트리 자료구조에 대해 알아보겠습니다.
Overview
- 개념
- 이진트리
- 순회
- 이진 탐색 트리
- 균형 이진트리
- AVL 트리
- 레드-블랙 트리
- Map, Set
- 힙
#0. 개념
1. 트리?
- [정의] : 트리는 1:n 관계의 계층 구조를 갖는 비선형 자료구조입니다. 트리는 노드로 구성되어, 각 노드의 연결 관계는 간선으로 표현합니다. 트리 자료구조는 사이클이 존재하지 않아 노드 간 계층 구조를 갖는 것이 특징입니다. 만약, 트리 자료구조의 노드 개수가 N개라면, 간선의 갯수는 N-1개입니다.
- [특징] : (1) 계층 구조 : 트리의 루트 노드는 부모 노드가 없지만, 그 외 노드들은 부모-자식 관계를 가지며 계층 구조를 형성합니다. (2) 간선의 방향성 : 트리의 간선은 항상 부모 -> 자식으로 방향성을 갖습니다. (3) 비순환 : 각 노드 사이의 간선은 오직 하나만 존재하고, 부모->자식으로 방향성을 갖기 때문에 트리 자료구조는 비순환 구조입니다.
2. 구성 요소
- 노드 : 트리를 구성하는 원소입니다.
- 간선 : 각 노드를 연결하는 혹은 연결 관계를 표현하는 선입니다.
- 깊이 : 루트 노드로부터 해당 노드까지 이동하는데 필요한 간선의 수를 깊이라고 합니다.
- 레벨 : 깊이에 1을 더한 값입니다. 루트 노드의 레벨은 1입니다.
- 높이 : 트리에서 가장 깊은 혹은 최대 레벨을 높이라고 합니다. 높이가 작을수록 효율적인 탐색이 가능합니다.
- 차수 : 노드가 가진 자식 노드의 개수입니다.
- 높이 - 노드 : 높이가 h인 이진트리는 최소 h+1개의 노드부터 최대 2^(h+1)-1 개의 노드까지 가질 수 있다.
#1. 이진 트리
1. 이진트리?

- [정의] : 이진트리는 트리 자료구조의 한 종류로 모든 트리의 차수를 2 이하로 제한하여 전체 트리의 차수가 2 이하입니다.
- [특징] : 이진트리의 각 노드는 왼쪽 서브트리와 오른쪽 서브 트리를 가집니다. 이진 트리는 부모-자식 관계가 하위 레벨에서도 순환적으로 반복되는 계층 구조를 형성하기 때문에, 이진 트리의 각 서브트리도 모두 이진 트리입니다.
2. 포화 이진트리
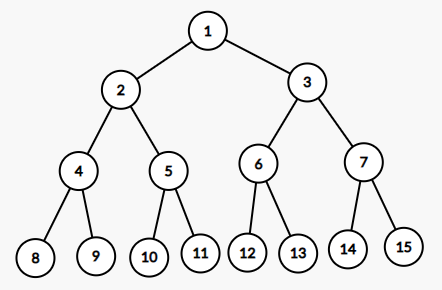
Details
- [정의] : 포화 이진트리는 모든 레벨에 노드가 꽉 차 높이를 늘이지 않는 한 노드를 추가할 수 없는 포화 상태의 이진트리입니다.
- [특징] : 포화 이진트리의 높이가 h일 때, 노드가 2^(h+1) - 1개입니다.
3. 완전 이진 트리
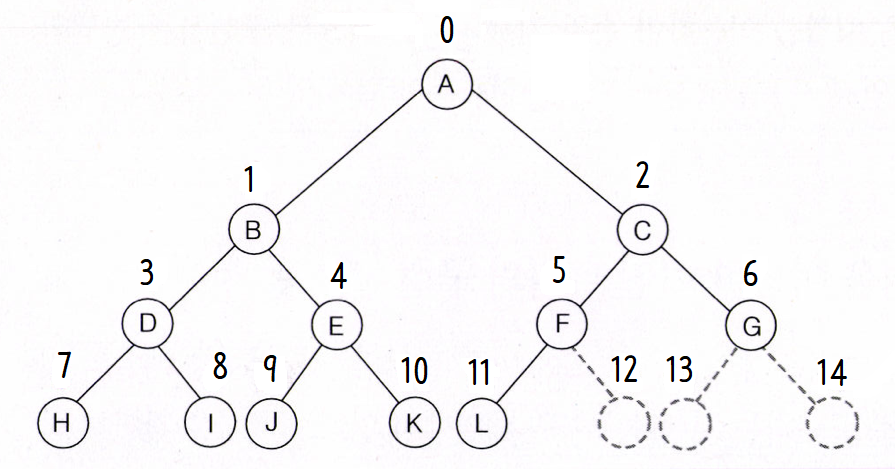
Details
- [정의] : 완전 이진트리는 마지막 레벨을 제외한, 모든 레벨에 노드가 꽉 차 있으며, 마지막 레벨의 노드는 왼쪽부터 차례대로 노드가 채워지는 이진트리입니다.
- [특징] : 총 노드 개수가 n일 때, n+1번 노드부터 2^(h+1)-1번 노드는 공백 노드로 채워집니다.
#2. 순회
1. 트리의 순회
- [정의] : 트리의 모든 노드를 탐색하는 순회 방법은 대표적으로 세 가지가 있습니다.
- [종류] : 트리의 세 가지 순회 방법은 전위 순회, 중위 순회, 그리고 후위 순회가 있습니다.
2. 전위 순회
struct Node {
int data;
Node* left;
Node* right;
};
void preorder(Node* root) {
if (root == nullptr) {
return;
}
cout << root->data << " "; // 현재 노드 값 출력
preorder(root->left); // 왼쪽 서브 트리 순회
preorder(root->right); // 오른쪽 서브 트리 순회
}
Details
- 트리의 전위 순회는 루트 노드, 왼쪽 서브 트리, 그리고 오른쪽 서브 트리 순서로 순회하는 방법입니다.
3. 중위 순회
struct Node {
int data;
Node* left;
Node* right;
};
void inorderTraversal(Node* root) {
if (root == nullptr) {
return;
}
inorderTraversal(root->left); // 왼쪽 서브 트리 순회
cout << root->data << " "; // 현재 노드 값 출력
inorderTraversal(root->right); // 오른쪽 서브 트리 순회
}
Details
- 트리의 중위 순회는 왼쪽 서브 트리, 루트 노드, 그리고 오른쪽 서브 트리 순서로 순회하는 방법입니다.
- 이진 탐색 트리에서 활용하는 순회 방법입니다.
4. 후위 순회
struct Node {
int data;
Node* left;
Node* right;
};
void postorderTraversal(Node* root) {
if (root == nullptr) {
return;
}
postorderTraversal(root->left); // 왼쪽 서브 트리 순회
postorderTraversal(root->right); // 오른쪽 서브 트리 순회
cout << root->data << " "; // 현재 노드 값 출력
}
Details
- 트리의 후위 순회는 왼쪽 서브 트리, 오른쪽 서브 트리, 그리고 루트 노드를 순서로 순회하는 방법입니다.
#3. 이진 탐색 트리
1. 이진 탐색 트리
- [정의] : 이진 탐색 트리는 이진 트리의 한 종류로, 각 노드는 값을 가지며, 각 노드의 왼쪽 자식 노드의 값은 해당 노드의 값보다 작거나 같고, 오른쪽 자식 노드의 값은 해당 노드의 값보다 크거나 같습니다.
2. 특징
- 모든 노드는 최대 두 개의 자식 노드를 가질 수 있으며, 각 노드는 값(혹은 키 값)을 가집니다.
- 왼쪽 자식 노드는 해당 노드의 값보다 작은 값을 가지며, 오른쪽 자식 노드는 반대로 큰 값을 가집니다.
- 이진 탐색 트리의 모든 서브 트리는 반드시 모두 이진 탐색 트리입니다.
3-1. 구현
#include <iostream>
using namespace std;
// 노드 클래스 정의
class Node {
public:
int key;
Node* left_child;
Node* right_child;
Node(int key) {
this->key = key;
left_child = nullptr;
right_child = nullptr;
}
};
// 이진 탐색 트리 클래스 정의
class BinarySearchTree {
private:
Node* root;
Node* insert(Node* node, int key) {
if (node == nullptr) {
node = new Node(key);
return node;
}
if (key < node->key) {
node->left_child = insert(node->left_child, key);
}
else if (key > node->key) {
node->right_child = insert(node->right_child, key);
}
return node;
}
Node* search(Node* node, int key) {
if (node == nullptr || node->key == key) {
return node;
}
if (key < node->key) {
return search(node->left_child, key);
}
else {
return search(node->right_child, key);
}
}
Node* deleteNode(Node* node, int key) {
if (node == nullptr) {
return node;
}
if (key < node->key) {
node->left_child = deleteNode(node->left_child, key);
}
else if (key > node->key) {
node->right_child = deleteNode(node->right_child, key);
}
else {
if (node->left_child == nullptr) {
Node* temp = node->right_child;
delete node;
return temp;
}
else if (node->right_child == nullptr) {
Node* temp = node->left_child;
delete node;
return temp;
}
Node* temp = getMinNode(node->right_child);
node->key = temp->key;
node->right_child = deleteNode(node->right_child, temp->key);
}
return node;
}
Node* getMinNode(Node* node) {
Node* current = node;
while (current->left_child != nullptr) {
current = current->left_child;
}
return current;
}
public:
BinarySearchTree() {
root = nullptr;
}
void insert(int key) {
root = insert(root, key);
}
Node* search(int key) {
return search(root, key);
}
void deleteNode(int key) {
root = deleteNode(root, key);
}
};
int main() {
BinarySearchTree bst;
bst.insert(5);
bst.insert(3);
bst.insert(7);
bst.insert(2);
bst.insert(4);
bst.insert(6);
bst.insert(8);
Node* found_node = bst.search(6);
if (found_node == nullptr) {
cout << "6을 찾지 못했습니다." << endl;
}
else {
cout << "6을 찾았습니다." << endl;
}
bst.deleteNode(3);
return 0;
}
Details
- Node 클래스 : Node 클래스는 이진 탐색 트리를 구성하는 노드를 정의하고 있습니다. 일반적으로 노드 자신이 갖는 키 값과 왼쪽 자식 노드 그리고 오른쪽 자식 노드를 갖습니다.
- BinarySearchTree 클래스 : 이진 탐색 트리 클래스를 정의합니다.
- Insert 함수 : Insert 멤버 함수는 기존의 이진 탐색 트리에 새로운 Key 값을 갖는 노드의 추가를 구현합니다. Insert 함수는 세 가지 경우를 고려합니다. 첫 번째 경우는 추가하고자 하는 이진 탐색 트리가 비어있을 경우입니다. 단순히 root 노드를 인자로 전달받은 키 값을 통해 동적 할당 받습니다. 두 번째 경우는 Key 값이 현재 노드의 Key 값 보다 작을 경우 입니다. 이럴 경우 현재 노드의 왼쪽 자식 노드를 인자로 Insert 함수를 재귀 호출합니다. 세 번째 경우는 Key 값이 현재 노드의 Key 값 보다 클 경우이며, 오른쪽 자식노드를 인자로 재귀호출 합니다. 정리하면, 이진 탐색트리의 현재 노드의 Key 값을 추가하고자 하는 Key 값과 비교하며 현재 노드가 비어있다면, 새롭게 Key 값을 추가하고, 그렇지 않다면 비교 결과를 통해 왼쪽 자식 노드 혹은 오른쪽 자식 노드로 옮겨가는 재귀 호출을 진행합니다.
- Search 함수 : Search 함수는 이진 탐색트리의 탐색을 구현합니다. 먼저, 이진 탐색 트리의 탐색 알고리즘은 중위 순회를 진행합니다. 루트 노드 -> 왼쪽 서브트리 -> 오른쪽 서브트리 순서대로 탐색을 진행합니다.
- Delete 함수 : Delete 함수는 이진 탐색 트리의 삭제를 구현합니다. 현재 노드의 Key 값과 비교해 왼쪽 자식 노드 혹은 오른쪽 자식 노드로 옮겨가며 삭제할 노드를 탐색하고, 삭제하고자 하는 노드가 자식 노드가 1개 일 경우, 그리고 2개 일 경우를 구현합니다.
- GetMinNode 함수 : GetMinNode는 단순히 이진 탐색 트리의 가장 왼쪽에 위치한 노드를 찾아 반환합니다.
3-2. 구현(배열 활용)
#include <iostream>
using namespace std;
// 배열로 이진 탐색 트리 구현
class BinarySearchTree {
private:
int* arr;
int max_size;
int current_size;
int getParentIndex(int i) {
return i / 2;
}
int getLeftChildIndex(int i) {
return 2 * i;
}
int getRightChildIndex(int i) {
return 2 * i + 1;
}
void swap(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
void resize() {
int* new_arr = new int[max_size * 2];
for (int i = 1; i <= current_size; i++) {
new_arr[i] = arr[i];
}
max_size *= 2;
delete[] arr;
arr = new_arr;
}
void insertRecursive(int i, int key) {
if (current_size >= max_size) {
resize();
}
if (arr[i] == 0) {
arr[i] = key;
current_size++;
return;
}
if (key < arr[i]) {
insertRecursive(getLeftChildIndex(i), key);
}
else if (key > arr[i]) {
insertRecursive(getRightChildIndex(i), key);
}
}
bool searchRecursive(int i, int key) {
if (arr[i] == key) {
return true;
}
if (key < arr[i] && arr[getLeftChildIndex(i)] != 0) {
return searchRecursive(getLeftChildIndex(i), key);
}
else if (key > arr[i] && arr[getRightChildIndex(i)] != 0) {
return searchRecursive(getRightChildIndex(i), key);
}
return false;
}
public:
BinarySearchTree(int max_size) {
arr = new int[max_size];
this->max_size = max_size;
current_size = 0;
}
void insert(int key) {
insertRecursive(1, key);
}
bool search(int key) {
return searchRecursive(1, key);
}
};
int main() {
BinarySearchTree bst(16);
bst.insert(5);
bst.insert(3);
bst.insert(7);
bst.insert(2);
bst.insert(4);
bst.insert(6);
bst.insert(8);
if (bst.search(6)) {
cout <<
Details
- 배열을 활용해 이진 탐색 트리를 구현하려면, 0번 인덱스는 사용하지 않고, 1번 인덱스부터 노드를 저장하는 것이 일반적입니다.
- 배열을 활용하여 이진 탐색 트리를 구현하면, 왼쪽 자식 노드는 해당 노드의 2*i 인덱스에 위치하며, 오른쪽 자식 노드는 해당 노드의 2*i+1 인덱스에 위치하도록 하는 것이 일반적입니다.
4. 탐색(이진 탐색)
// 이진 탐색 트리에서의 탐색 알고리즘 구현
bool search(Node* root, int target) {
// 루트 노드가 NULL이면 트리가 비어있으므로 탐색 실패
if (root == NULL) {
return false;
}
// 현재 노드의 값이 탐색 대상 값과 같으면 탐색 성공
if (root->value == target) {
return true;
}
// 현재 노드의 값이 탐색 대상 값보다 크면 왼쪽 서브트리에서 다시 탐색
if (root->value > target) {
return search(root->left, target);
}
// 현재 노드의 값이 탐색 대상 값보다 작으면 오른쪽 서브트리에서 다시 탐색
else {
return search(root->right, target);
}
}
Details
- 기본적으로 이진 탐색 트리의 탐색은 이진 탐색 알고리즘과 동일합니다.
- 이진 탐색 트리의 순회는 "중위 순회"입니다.
- 따라서, 루트 노드에서 시작해서 현재 노드의 값이 찾고자 하는 값과 같으면 성공. 현재 노드의 값이 찾고자 하는 값보다 크면 왼쪽 서브트리에서 다시 탐색을 진행. 반대로 크다면, 오른쪽 서브트리에서 다시 탐색을 진행합니다.
- 이진 탐색 트리의 탐색 알고리즘의 평균 시간 복잡도는 O(log n)으로, 최악의 경우 시간 복잡도는 O(h(높이))입니다.
4. 성능
- [접근(탐색)] : 평균 시간 복잡도는 O(log n)입니다. 반대로, 최악 시간 복잡도는 O(n)입니다.
- [삽입] : 평균 시간 복잡도는 O(log n)입니다. 반대로, 최악 시간 복잡도는 O(n)입니다.
- [제거] : 평균 시간 복잡도는 O(log n)입니다. 반대로, 최악 시간 복잡도는 O(n)입니다.
- [이유] : 탐색/삽입/제거 알고리즘 모두 트리의 높이에 따라 성능이 결정됩니다. 트리의 높이 균형이 무너져(왼쪽 서브트리의 높이와 오른쪽 서브트리의 높이 차가 2이상일 경우) 편향 이진 트리를 형성할 경우 트리의 모든 노드를 순차적으로 탐색해야 하므로 O(n)의 최악 시간 복잡도를 갖습니다.
#4. 균형 이진 트리
1. 균형 이진트리?
- [정의] : 균형 이진트리는 이진트리의 왼쪽 서브트리와 오른쪽 서브트리의 높이 차이를 최소화하여 탐색/삽입/삭제 연산의 성능을 향상한 이진트리입니다. 편향 이진 트리가 보여주는 최악의 탐색성능을 보완하기 위한 이진 트리이기도 합니다.
- [특징] : 균형 이진트리는 탐색/삽입/삭제 연산의 최악 시간 복잡도를 평균 시간 복잡도 O(log n)으로 향상시켜 유지시키기 위한 이진 트리의 특수한 형태입니다.
2. 특징
- [높이 균형] : 균형 이진 트리는 모든 리프 노드들이 같은 높이에 있거나, 최악의 경우 높이 차이가 1인 상태를 유지합니다. 이러한 높이 균형은 탐색/삽입/삭제 연산의 성능을 평균 시간 복잡도로 유지하는 핵심적인 역할을 합니다.
- [자가 균형성(Self-Balancing)] : 균형 이진 트리는 자가 균형성을 갖습니다. 삽입/삭제 등의 연산을 수행한 후에도 트리의 높이 균형을 자동으로 조정합니다.
- [데이터 정렬] : 일반적으로, 이진 탐색 트리에서 데이터가 이미 정렬된 상태라면, 데이터가 모두 왼쪽 혹은 오른쪽으로 삽입되어 편향 이진트리가 형성됩니다. 이러한 현상은 트리의 높이 균형이 무너져 탐색/삽입/삭제 연산의 성능이 최악 시간 복잡도를 보여줍니다. 하지만, 균형 이진트리는 자가 균형성의 특성을 통해 탐색 알고리즘의 성능을 평균 시간 복잡도를 유지합니다.
#5. AVL 트리
1. AVL(Adelson-Velsky&Landis) 트리

Details
- [정의] : AVL트리는 균형 이진 트리의 한 종류로, 모든 노드의 왼쪽 서브트리와 오른쪽 서브트리의 높이 차가 최대 1인 이진 트리입니다. AVL트리는 왼쪽 서브트리와 오른쪽 서브트리의 높이 균형 유지를 위해 삽입/삭제 연산 시 회전을 통해 정렬 작업을 수행합니다.
- [특징] : (1) 높이 차 1이하 : AVL트리는 모든 노드의 왼쪽 서브트리와 오른쪽 서브 트리의 높이 차가 최대 1인 높이 균형 트리입니다. (2) 정렬 작업 : AVL트리는 노드를 삽입/삭제할 때, 트리의 높이 균형 성질을 유지하기 위해 회전 연산을 수행합니다.
- [정렬] : AVL트리의 회전 연산은 총 4가지 경우로 나 누이 집니다-LL, RR, LR, RL
- [성능] : AVL트리의 탐색/삽입/삭제 연산은 모두 O(log n)의 시간 복잡도를 가지며, 삽입/삭제 연산 시 추가적으로 회전 연산을 수행하기 때문에 일반적인 이진 탐색 트리보다 삽입/삭제 연산이 느릴 수 있습니다.
2. BF(Balance Factor)
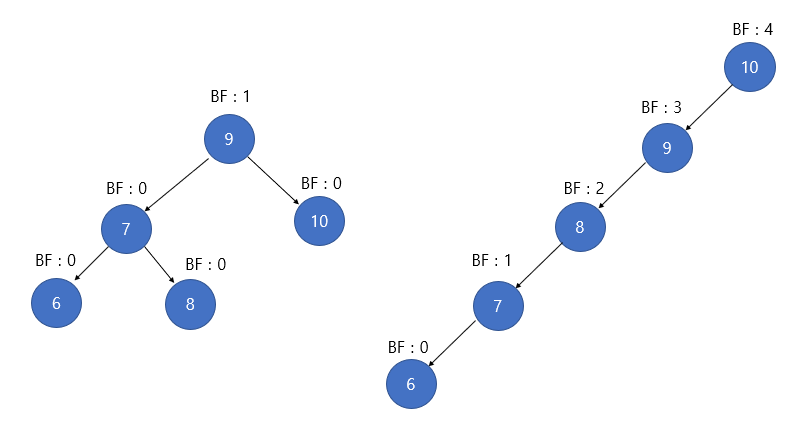
BF(K) = K의 왼쪽 서브트리의 높이 - K의 오른쪽 서브트리의 높이
Details
- [정의] : BF는 트리의 현재 균형 정도를 파악하고 회전 연산의 필요여부를 판단하기 위해 활용됩니다.
- [특징] : 일반적으로, 균형 이진트리의 각 노드는 -1 ~ 1을 유지하며, 해당 범위를 벗어났을 때 회전 연산이 필요합니다. BF와 함께 총 네 가지 경우(LL, RR, LR, RL)를 고려해 회전 연산을 수행합니다.
3. LL(Left Left) 케이스
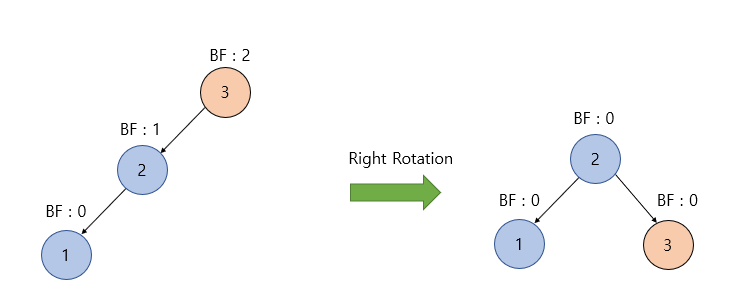
Details
- [정의] : 왼쪽 자식 노드의 왼쪽에 노드가 추가되어, 높이 균형이 깨지는 경우를 LL 경우라고 합니다.
- [동작 방식] : "오른쪽 회전", 왼쪽 자식 노드(2)가 루트 노드가 되고, 이전에 루트 노드였던 노드(3)를 오른쪽 자식 노드로 변경합니다.
4. RR(Right Right) 케이스

Details
- [정의] : 오른쪽 자식 노드의 오른쪽에 노드가 추가되어, 높이 균형이 깨지는 경우를 RR 경우라고 합니다.
- [동작 방식] : "왼쪽 회전", 오른쪽 자식 노드(2)를 루트 노드로 변경하고, 이전에 루트 노드(1)였던 노드를 왼쪽 자식 노드로 변경합니다.
6. LR(Left Right) 케이스

Details
- [정의] : 왼쪽 자식 노드의 오른쪽에 노드가 추가되어, 높이 균형이 깨지는 경우를 LR 경우라고 합니다.
- [동작 방식] : "왼쪽 회전 + 오른쪽 회전", 먼저, RR회전을 통해 왼쪽 자식 노드(2)의 오른쪽 서브트리(3)를 해당 서브트리의 루트 노드(원래 2가 있던 자리)로 변경하고, 이렇게 변경된 서브트리의 루트 노드와 상위 루트 노드(4)의 LL 회전을 수행합니다. 정리하자면, G(조상), P(부모), S(자식) 중 P와 S의 RR회전, G와 P의 LL회전
6. RL(Right Left) 케이스

Details
- [정의] : 오른쪽 자식 노드의 왼쪽에 노드가 추가되어, 높이 균형이 깨지는 경우를 RL 경우라고 합니다.
- [동작 방식] : "올라오며 오른쪽 회전 + 외쪽 회전", 먼저, LL회전을 통해 오른쪽 자식 노드(4)의 왼쪽 서브트리(3)를 해당 서브트리의 루트 노드(원래 4가 있던 위치)로 변경하고 이전의 루트 노드(4)를 오른쪽 서브트리로 변경, 그리고 변경된 루트 노드(3)와 상위 루트 노드(2)의 RR 회전을 수행합니다. 정리하면, G(조상), P(부모), S(자식) 중 P와 S의 LL회전, 그리고 G와 P의 RR회전
6. 정리
| 경우 | 1차 회전 | 2차 회전 |
| LL(R 회전) | G노드와 P노드의 자리 변경, G노드를 P노드의 오른쪽 자식 노드로 |
|
| RR(L 회전) | G노드와 P노드의 자리 변경, G노드를 P노드의 왼쪽 자식 노드로 |
|
| LR(L회전 + R회전) | P노드와 S노드의 RR회전 | G노드와 P노드의 LL회전 |
| RL(R회전 + L회전) | P노드와 S노드의 LL회전 | G노드와 P노드의 RR회전 |
#6. 레드-블랙 트리
1. 개념 및 설명
[자료구조]#4_레드-블랙 트리
[자료구조]#4_레드-블랙 트리 레드-블랙 트리에 대해 알아보겠습니다. Overview 개념 정렬 방법 #0. 개념 1. 레드-블랙 트리? 레드-블랙 트리는 검색, 삽입, 삭제 등의 연산을 최악의 경우 O(log n)의 시
webddevys.tistory.com
#7. Map, Set
1. Map
[Basic C++] #38_map, 연관 컨테이너
[Basic C++] #38_map, 연관 컨테이너 C++ 개발에서 표준 라이브러리(STL)의 "map"에 대해 알아보겠습니다. "전문가를 위한 C"의 16 항목, "컨테이너와 반복자 이해하기"에 해당하는 내용입니다. Overview 개념
webddevys.tistory.com
2. Set
[Basic C++] #29_Set, MultiSet, STL 컨테이너
[Basic C++] #29_Set, MultiSet, STL 컨테이너 C++ 개발에서 STL 컨테이너에 대해 알아보겠습니다. C++가 제공하는 STL 컨테이너 중 Set과 MultiSet을 살펴보겠습니다. Set 1. 개념 Set은 STL에서 제공하는 연관 컨테
webddevys.tistory.com
#8. 힙
1. 힙?
- [정의] : 힙은 반 정렬 상태를 유지하는 완전 이진트리의 한 종류입니다. 힙은 두 종류로, 먼저, 최대 힙은 트리의 계층 구조에서 부모 노드의 값은 자식 노드의 값보다 크거나 같은 형대를 유지하고, 최소 힙은 부모 노드의 값이 자식 노드의 값보다 작거나 같은 형태를 유지합니다.
- [특징] : 힙은 우선순위 큐를 구현하기에 적합합니다. 힙은 각 노드의 값에 따라서 부모-자식 관계가 형성되어, 노드 별 우선순위에 따라서 제거 순서가 달라지기 때문입니다.
- [성능] : 힙은 최선, 평균, 그리고 최악의 경우 모두 O(log n)의 시간 복잡도를 갖습니다. 힙의 삽입/제거 작업 모두 정렬 작업을 수행하며, 이 정렬 작업은 최악의 경우 힙의 높이 만큼 비교 연산을 수행하기 때문입니다.
2. 삽입
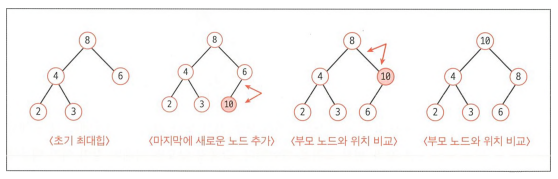
- 최대 힙에 새로운 항목이 삽입되면 일반적으로 해당 노드는 마지막 노드 다음 위치에 추가됩니다.
- 새로운 노드는 부모 노드와 값을 비교해 새로운 노드의 값이 더 크거나 같다면 새로운 노드와 부모 노드의 위치를 변경합니다. 해당 과정을 새로운 노드가 힙의 올바른 위치에 도달할 때까지 반복합니다.
3. 제거
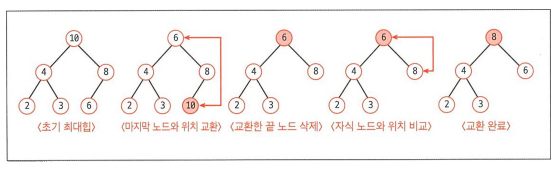
- 힙에서의 삭제 혹은 제거 연산은 루트 노드의 제거를 의미합니다.
- 루트 노드의 제거 후 힙의 특성을 유지하기 위해 마지막 노드를 루트 노드의 위치로 변경합니다.
- 변경된 루트 노드를 자식 노드들과 비교하며 올바른 자리를 찾아갑니다.
* 힙의 삽입 연산은 새로운 노드를 마지막 위치에 삽입해 부모 노드들과 비교하며 올바른 자리를 찾아가며,
힙의 삭제 연산은 마지막 노드를 루트 노드로 변경해 자식 노드들과 비교하며 올바른 자리를 찾아갑니다.
4. 구현-1
#include <iostream>
#include <vector>
using namespace std;
class MinHeap {
private:
vector<int> heap;
// 특정 인덱스에 해당하는 노드의 부모 노드 인덱스를 반환하는 함수
int parent(int i) {
return (i - 1) / 2;
}
// 특정 인덱스에 해당하는 노드의 왼쪽 자식 노드 인덱스를 반환하는 함수
int left(int i) {
return 2 * i + 1;
}
// 특정 인덱스에 해당하는 노드의 오른쪽 자식 노드 인덱스를 반환하는 함수
int right(int i) {
return 2 * i + 2;
}
// 두 노드 중 작은 값을 반환하는 함수
int getSmallerIndex(int i, int j) {
if (heap[i] < heap[j])
return i;
else
return j;
}
public:
// 새로운 노드를 추가하는 함수
void push(int key) {
heap.push_back(key);
int i = heap.size() - 1;
// 새로운 노드가 부모 노드보다 작을 경우, 부모 노드와 위치를 바꿔준다
while (i > 0 && heap[parent(i)] > heap[i]) {
swap(heap[parent(i)], heap[i]);
i = parent(i);
}
}
// 힙에서 최소값을 제거하고 반환하는 함수
int pop() {
if (heap.empty())
throw runtime_error("Heap is empty");
int root = heap[0];
// 힙의 마지막 노드를 루트 노드로 옮긴다
heap[0] = heap[heap.size() - 1];
heap.pop_back();
// 힙을 재구성한다
int i = 0;
while (left(i) < heap.size()) {
int j = getSmallerIndex(left(i), right(i));
if (heap[i] > heap[j]) {
swap(heap[i], heap[j]);
i = j;
} else {
break;
}
}
return root;
}
};
Details
- 힙을 구현하는 첫 번째 방법은 배열을 활용하는 방법입니다.
- 일반적으로 배열을 활용해 힙을 구현할 경우, 부모 노드는 (N-1)/2이며, 왼쪽 자식 노드는 2 * N + 1, 그리고 오른쪽 노드는 2 * N + 2입니다. 주의할 점은 0 베이스의 인덱싱을 수행하고자 한다면 위 방법을 활용하며, 1번 인덱스를 루트 노드로 설정할 경우, 왼쪽 자식 노드는 2 * N, 그리고 오른쪽 자식 노드는 2 * N + 1로 설정합니다.
- push() 함수는 힙에 새로운 노드를 삽입하는 함수입니다. 이때, 새로운 노드는 heap.size()-1(힙의 마지막 위치)에 삽입되어 부모 노드를 올라가며 제자리를 찾아갑니다.
- pop() 함수는 힙으로부터 루트 노드를 제거하는 함수입니다. 이때, 비어 있는 루트 노드의 자리는 힙의 마지막 노드로 변경됩니다. 그리고, 해당 노드를 자식 노드들과 비교해 가며 제자리를 찾습니다.
5. 구현-2
#include <iostream>
class MinHeap {
private:
struct Node {
int data;
Node* next;
Node(int value) : data(value), next(nullptr) {}
};
Node* root;
public:
MinHeap() : root(nullptr) {}
void push(int value) {
Node* newNode = new Node(value);
if (root == nullptr || value < root->data) {
newNode->next = root;
root = newNode;
} else {
Node* current = root;
while (current->next != nullptr && value >= current->next->data) {
current = current->next;
}
newNode->next = current->next;
current->next = newNode;
}
}
int pop() {
if (root == nullptr) {
return -1; // or throw an exception
}
int rootValue = root->data;
Node* temp = root;
root = root->next;
delete temp;
return rootValue;
}
bool isEmpty() const {
return root == nullptr;
}
~MinHeap() {
while (root != nullptr) {
Node* temp = root;
root = root->next;
delete temp;
}
}
};
int main() {
MinHeap minHeap;
minHeap.push(5);
minHeap.push(2);
minHeap.push(8);
minHeap.push(1);
while (!minHeap.isEmpty()) {
std::cout << minHeap.pop() << " ";
}
return 0;
}
Details
- 힙을 구현하는 두 번째 방법은 연결 리스트를 활용하는 방법입니다.
'언어 > 자료구조' 카테고리의 다른 글
| [자료구조]#7_우선순위 큐 (0) | 2023.08.11 |
|---|---|
| [자료구조]#6_그래프 (1) | 2023.05.25 |
| [자료 구조]#0_선형 자료구조 (0) | 2023.04.06 |
| [자료구조]#4_레드-블랙 트리 (0) | 2023.04.06 |
| [자료구조]#3_이중 연결 리스트(Double Linked List) (0) | 2022.12.25 |